In ranked distribution, assumptions drive the process. Rankings determine outcomes, shaping expectations. Each position carries weight. Choices reflect priorities. Active engagement influences results, shaping collective experiences. Echoes of intention resonate throughout the structure. Flexibility enhances adaptability. Understanding the dynamics fosters collaboration and harmony. Consensus emerges through respectful interactions. Leadership and followership interplay to sustain equilibrium. Mutual trust propels growth. Transparency reinforces credibility. Balancing individual needs with the common good involves continuous adjustments. Acknowledging complexities nurtures creativity. Iterative cycles foster evolution. Embracing diversity enriches perspectives. Recognizing interdependencies empowers collective progress. The assumption of ranked distribution unfolds a tapestry of interconnected possibilities.
Table of Contents
- Applications of ranked distribution
- Common misconceptions about ranked distribution
- Definition of ranked distribution
- Importance of understanding ranked distribution
- Methods for analyzing ranked distribution
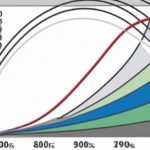
(OW2 rank distribution curve post-season 12)
The assumption of ranked distribution is a statistical concept used in various fields such as economics, sociology, and psychology. It refers to the belief that data points can be ordered based on their magnitudes. This assumption is important as it allows researchers to analyze and interpret data more effectively. By ranking data points, researchers can identify patterns, trends, and relationships within the data set. For example, in a study measuring income levels across different demographics, the assumption of ranked distribution would allow researchers to compare and contrast the income levels of various groups.
In practice, the assumption of ranked distribution is often used in correlation analysis, regression analysis, and hypothesis testing. It provides a framework for understanding the relationships between variables and making predictions based on the data. However, it is important to note that the assumption of ranked distribution is just that – an assumption. While it can be a useful tool, researchers should always be cautious and critically evaluate their data to ensure its validity and reliability. Ultimately, the assumption of ranked distribution serves as a foundational principle in statistical analysis, helping researchers make sense of complex data sets and draw meaningful conclusions.
Applications of ranked distribution
When delving into the fascinating realm of ranked distribution, one can’t help but marvel at its diverse applications. These applications offer valuable insights across various fields, shedding light on rankings and their significance in decision-making processes.
In the field of economics, ranked distribution proves to be a powerful tool for analyzing income disparities within societies. By categorizing individuals based on their income levels and arranging them in a ranked order, economists can gain a deeper understanding of wealth distribution patterns. This information is crucial for policymakers striving to promote economic equality and social welfare.
Moving beyond economics, the realm of sports also benefits significantly from ranked distribution analysis. Whether it’s determining player standings in a tournament or evaluating team performance over a season, ranking systems play a pivotal role in assessing athletic prowess. Fans eagerly follow these rankings, adding an element of excitement and anticipation to competitive events.
Moreover, healthcare professionals harness the power of ranked distribution when prioritizing patient care based on severity levels. In emergency rooms bustling with activity, triage systems rely on ranking patients according to the urgency of their medical needs. This structured approach ensures that critical cases receive prompt attention, potentially saving lives in high-stress situations.
The world of academia isn’t left untouched by the influence of ranked distribution either. From university admissions processes to academic journal rankings, institutions use this methodology to make informed decisions about student selection and research impact assessment. The competitive nature inherent in rankings spurs individuals towards excellence while guiding institutional policies towards continuous improvement.
Beyond professional spheres, even everyday scenarios like restaurant reviews or hotel ratings demonstrate how ubiquitous ranked distributions have become in modern society. Consumers rely on these rankings to make informed choices about where to dine or stay based on others’ experiences—a testament to the pervasive influence wielded by such methodologies.
In essence, applications of ranked distributions permeate numerous facets of our lives, offering structure and insight where complexity reigns supreme. Through careful analysis and interpretation of these rank-based systems, we navigate uncertainties with greater clarity and purpose—unlocking hidden patterns that shape our understanding of the world around us.
Common misconceptions about ranked distribution
When it comes to ranked distribution in various fields like gaming or academic grading, there are plenty of misconceptions that can stir up some heated debates. Let’s dive into these assumptions and unravel the truths behind them.
One common misconception is that ranks accurately represent an individual’s true skill level. People often believe that if they achieve a higher rank, they must be more skilled than those with lower ranks. But hey, hold on! Ranks are influenced by numerous factors like luck, teamwork, and even the current meta in games. So don’t beat yourself up if you’re not topping the charts just yet!
Another myth floating around is that ranking systems are always fair and unbiased. Well, hate to break it to you folks! Sometimes these systems have flaws or biases built into them which can skew results unfairly against certain groups of players or students. It’s important to recognize these limitations and work towards creating a more equitable ranking environment for everyone involved.
Now let’s talk about the idea that climbing up the ranks guarantees everlasting success and happiness. While seeing your rank go higher can be exhilarating at first, remember it’s not all rainbows and butterflies once you reach the top. The pressure to maintain your position can be overwhelming, leading to stress and burnout if not managed properly.
Lastly, there’s this notion that reaching the highest rank makes you invincible or superior to others around you – kind of like being crowned king of the hill. But guess what? No matter how high your rank may be, there will always be challenges ahead that test your skills and resilience. It’s essential to stay humble and keep improving rather than resting on past achievements.
In conclusion, ranked distribution is a multifaceted concept filled with complexities beyond just numbers on a screen or grades on a paper. By understanding and debunking these common misconceptions, we pave the way for a more enlightened approach towards rankings – one driven by fairness, continuous growth, and above all else: fun!
Definition of ranked distribution
When we talk about the concept of ranked distribution, we are delving into a statistical method that organizes data points in numerical order from lowest to highest value. Imagine lining up a group of numbers according to their magnitude, like arranging players based on their scores in a tennis tournament. This structured arrangement helps us gain insights into the relative positions and relationships within the dataset.
In simpler terms, ranked distribution assigns each element in a set with a unique rank or position based on its value compared to others. For example, if you have test scores ranging from 60 to 90, ranking them would reveal who scored higher or lower than others. It’s like creating a leaderboard where everyone can see where they stand among their peers.
The beauty of ranked distribution lies in its ability to make comparisons and draw conclusions without getting lost in individual values—like finding out who aced the exam without knowing exact marks but having an idea of relative performance. This method brings clarity to complex datasets by organizing information systematically for easier interpretation.
Think of it as giving every piece of data a specific seat at the table—a way to understand not just what each number represents but also how it relates to others around it. It’s like putting together puzzle pieces to see the bigger picture emerge gradually.
Ranked distribution isn’t just about sorting numbers; it’s about revealing patterns and trends hidden within raw data. By assigning ranks, we create hierarchies that showcase disparities and similarities among different elements—a visual representation of standing shoulder-to-shoulder with your peers based on performance levels.
Emotionally speaking, ranked distribution offers both clarity and competition—it shows us where we excel or lag behind while fostering healthy rivalries and motivating improvement efforts. There’s excitement in seeing your name climb up the leaderboard and satisfaction in knowing where you stack up against others.
So next time you encounter ranked distribution in statistics, remember—it’s more than just numbers lined up neatly; it’s an intricate web of relationships waiting to be deciphered for deeper understanding.
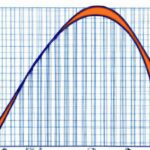
(Ranked Distribution In Apex Compared To Valorant)
Importance of understanding ranked distribution
Understanding ranked distribution is like deciphering a complex puzzle that holds the key to unlocking hidden patterns in data. It’s not just about numbers; it’s about unraveling stories, trends, and insights that can shape decisions with precision. Imagine each data point as a player in a game of musical chairs – their position matters, and how they are ranked determines the outcome.
When we talk about the importance of grasping ranked distribution, we are delving into the heart of statistical analysis where every rank carries weight and significance. Picture a sea of figures arranged from highest to lowest or vice versa – this order isn’t random but purposeful. Each ranking signals something crucial about its place within the dataset.
By comprehending ranked distribution, we gain clarity on where values stand relative to one another. It’s like having a map that guides us through peaks and valleys, showing which entries shine bright at the top or linger in shadows at the bottom. This insight empowers decision-makers to spot outliers swiftly, identify trends effortlessly, and detect anomalies promptly.
The beauty of understanding ranked distribution lies in its ability to simplify complexity without losing depth. It’s akin to seeing constellations emerge from scattered stars – suddenly, chaos transforms into cosmos as patterns start taking form before our eyes.
Moreover, mastering this concept allows us to navigate uncertainty with confidence. Just as sailors once relied on stars for navigation across tumultuous seas, so too can we find guidance amidst turbulent data by interpreting ranks with finesse.
In essence, diving deep into ranked distribution opens doors to realms where intuition meets intellect; where gut feelings merge seamlessly with analytical prowess; where art dances harmoniously with science. It transcends mere statistics and evolves into an art form that reveals truths hiding beneath numerical facades.
So next time you encounter rows upon rows of rankings in your dataset, remember: they’re not just symbols on a page but gateways to understanding that promise revelations if only you dare explore their depths.
Methods for analyzing ranked distribution
Analyzing ranked distribution is like unraveling a mystery within data, where each rank holds a piece of the puzzle. Imagine diving into a sea of numbers, searching for patterns that can reveal underlying truths. There are various methods to tackle this task, each offering unique insights and challenges.
One common approach is using percentile ranks, which divide the data into hundred equal parts based on their position in the ranking. This method helps us understand how individual values compare to the overall distribution. It’s like placing each number on a ladder and seeing where it stands in comparison to others – some near the top basking in glory while others languish at the bottom.
Another powerful tool is quartile analysis, which splits data into four equal parts representing different segments of the distribution. By looking at these quartiles – from lowest to highest – we gain a nuanced understanding of how values are spread out and clustered around certain points. It’s akin to slicing a cake into quarters and savoring each portion separately, appreciating its unique flavor profile.
Moving beyond simple measures, we encounter more sophisticated techniques such as skewness and kurtosis analysis. Skewness reveals whether our ranked distribution leans towards one side or another, indicating asymmetry in the data spread. Picture balancing weights on a seesaw – if one end dips lower than the other, you know there’s an imbalance waiting to be explored.
Kurtosis goes deeper by exploring how heavily ranked values cluster around the mean compared to a normal distribution curve. A high kurtosis suggests peaks and sharp drops in our dataset resembling jagged mountains rather than gentle hillsides. It’s like wandering through terrain filled with spikes and valleys instead of smooth rolling plains.
As we navigate these diverse methods for analyzing ranked distributions, emotions may run high – frustration when faced with complexity but also exhilaration upon uncovering hidden trends buried beneath numerical facades. The journey through this analytical landscape is not just about crunching numbers; it’s about unearthing stories whispered by data points waiting to be heard.
External Links
- The Wilcoxon Rank Sum Test | UVA Library
- Does every smooth integrable constant-rank distribution have a …
- Distribution of the Spearman rank correlation coefficient under the …
- The Use of Ranks to Avoid the Assumption of Normality Implicit in …
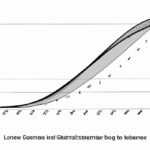
- CS:GO rank distribution after they update the ranking system 12/14 …